GPT-1(2018年)は「事前学習+微調整」という現在の主流パラダイムを確立しました。GPT-2(2019年)はゼロショット学習を示し、規模が増すほど性能が伸びることを実証しています。
モデル
182
GPT-1 / GPT-2 系
ジーピーティー ワン ジーピーティー ツー
体験区分:調査ベース
推奨読者レベル:Level 2-3
何をしてくれるか
どこで出会うか
AI 史の説明文脈で登場します。「なぜ今のモデルはこれほど賢いのか」を辿ると、必ずこの世代に行き着きます。GPT-2 の段階公開は AI 安全性の先例として今も引用されます。
イメージ
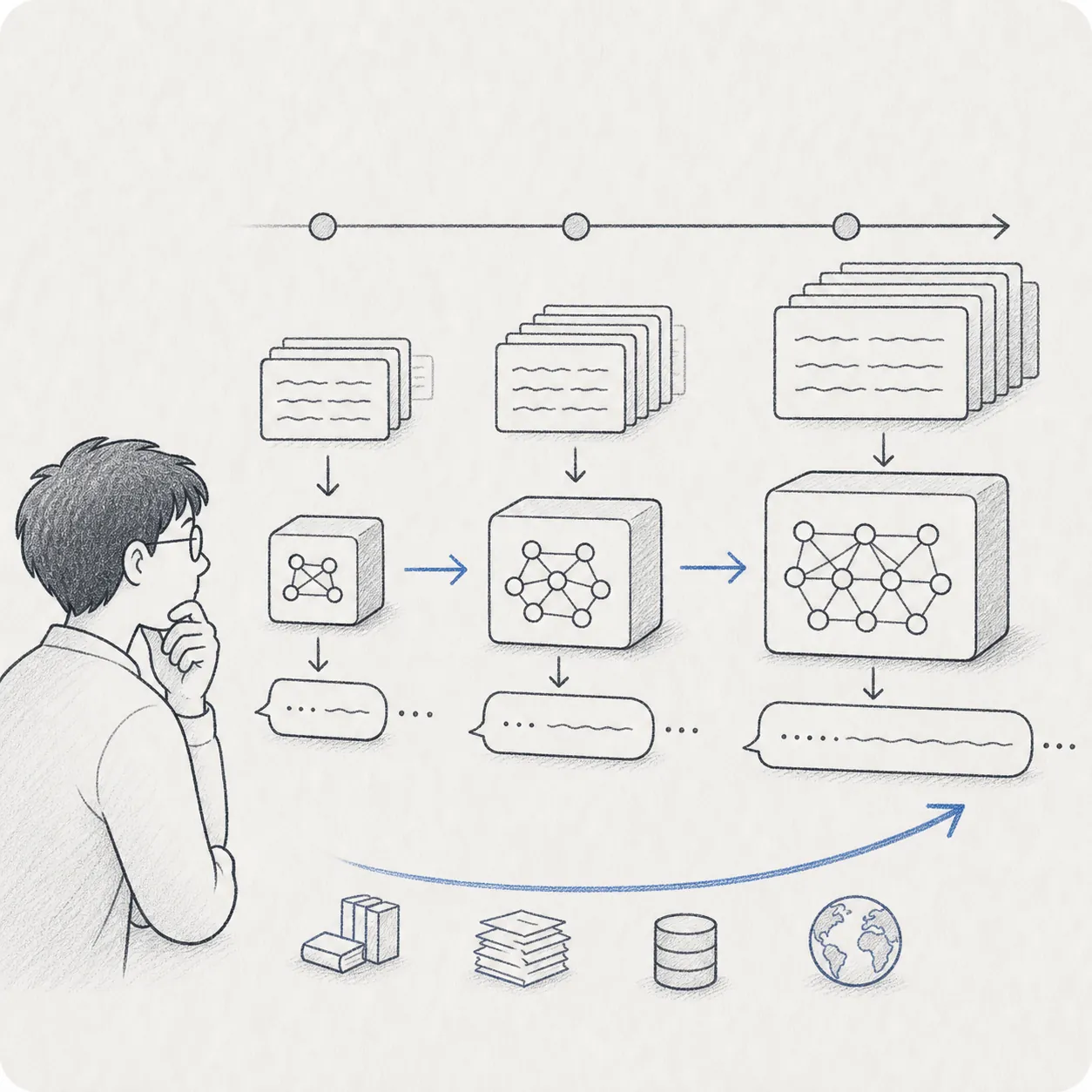
開発フローでの位置
前提知識として押さえる
現行モデルとの差異を掴む
用語の出所を追う
安全性の議論を理解する
2026.04·ready
「GPT-2 の段階公開は Scaling Law の可能性に OpenAI が気づいた転換点ですよね。」
GPT-1 / GPT-2 系の見方
183
この用語の見どころ
1
役割
現代 LLM の原型。事前学習+微調整の枠組みを確立しました。
2
うれしさ
Scaling Law の起点を知ると現在のモデル競争の理由が腑に落ちます。
3
注意点
廃止済みで実用では使いません。歴史知識として扱います。
4
どこで役立つか
AI 開発の経緯や大規模化の背景を説明する場面。
5
はじめに
GPT-1 論文の「事前学習+微調整」という概念が核心です。
6
深掘り先
GPT-3 系、Transformer 論文、Scaling Law
非エンジニアのつまずき
- GPT-3 から認知し始めたので、2 という数字が何を意味するのか分かりません
- これを覚えても、役に立つことはあまりなさそうな印象を受けます
私のコメント
- 第一印象:GPT-3 以降に触れた身として、振り返っておきたい世代です
- 良い点:従来主流だったディープラーニング系と別系統から出てきた点がすごいです
- ダメな点:性能的にはまだ実用化には遠い段階です
- 誰向けか:AI の歴史を学びたい人向けです
関連用語
備考
GPT-1 パラメータ数: 約 1.17 億(117M) GPT-2 パラメータ数: 最大 15 億(1.5B)。
D-25·model
バイブコーディング図鑑