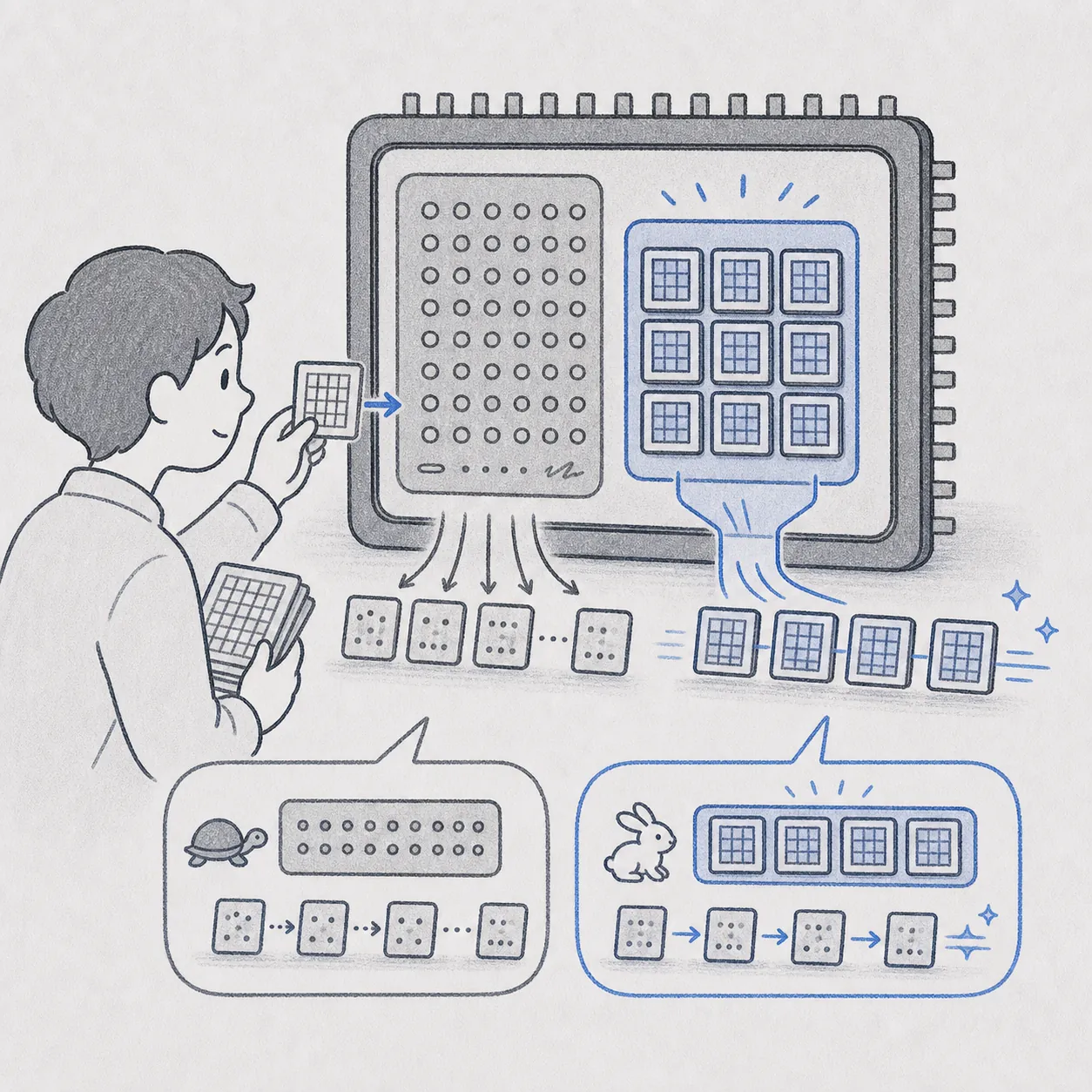
行列の掛け算(GEMM)を汎用コアより高速に処理します。FP16・BF16・FP8 など混合精度演算に対応し、LLM の学習や推論で必要な大規模行列計算を短時間でこなせます。
一般語彙
618
Tensor コア
テンサー コア
体験区分:調査ベース
推奨読者レベル:Level 4-5
何をしてくれるか
どこで出会うか
GPU スペック表や AI 学習環境の選定記事で「Tensor コア数 × 世代」として登場します。H100・RTX 40 シリーズ選びで TFLOPS を比較する場面が代表的です。
イメージ
開発フローでの位置
モデル設計
GPU 選定
混合精度設定
学習・推論実行
コスト評価
2026.04·ready
「H100 は Tensor コアが FP8 対応なので、訓練速度が前世代と段違いです。」
Tensor コアの見方
619
この用語の見どころ
1
役割
GPU 内で行列演算だけを高速処理する専用ユニットです。
2
うれしさ
LLM 学習・推論の所要時間が大幅に短縮できます。
3
注意点
世代ごとに対応精度が異なり、FP8 は H100 以降でのみ有効です。
4
どこで役立つか
GPU 選定や訓練コスト試算の場面で判断基準になります。
5
はじめに
「行列演算を速くする専用コア」という役割を押さえれば十分です。
6
深掘り先
GPU、H100、量子化
非エンジニアのつまずき
- CUDA コアと Tensor コアの違いや行列計算の仕組みがイメージしきれません。
私のコメント
- 第一印象:行列計算に特化したコアかな、という想像で入りました。
- 良い点:世代ごとに強くなり LLM の性能向上とコスト低減に効いている点です。
- ダメな点:正直よく分かりません。立ち位置を正しく説明できるかで止まります。
- 誰向けか:原理原則を理解したい人向けです。
関連用語
備考
Tensor コアは 2017 年 Volta(V100)で初登場、Turing(RTX 20 シリーズ)以降コンシューマー向けにも展開 世代別対応精度の目安:Volta FP16 → Amp…
J-75·term_general
バイブコーディング図鑑