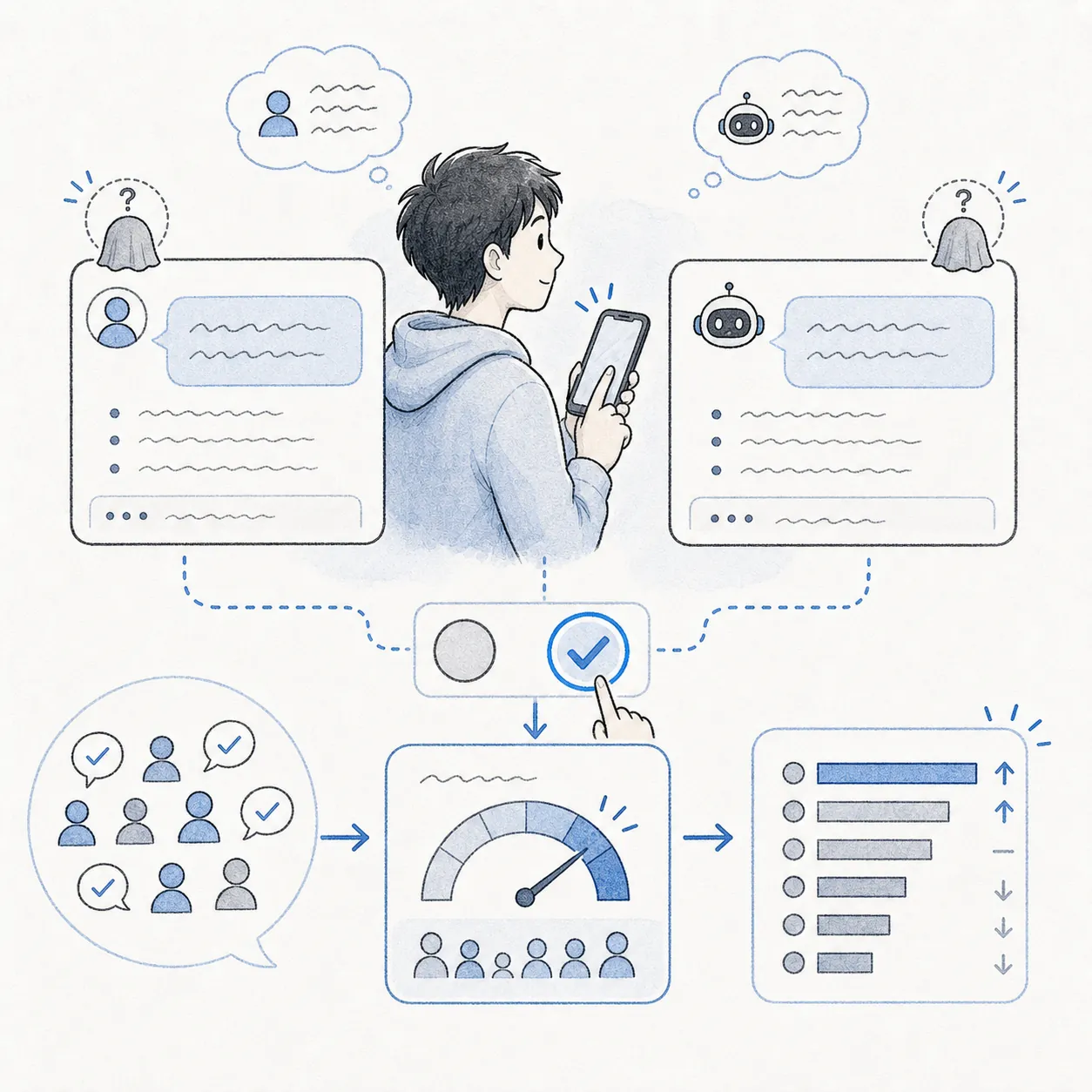
どのモデルが優れているかを「人間の感覚」で評価します。2 モデルに同じ質問を投げて勝者を投票し、その結果を ELO レーティングで集計します。
ベンチマーク
264
Chatbot Arena
チャットボットアリーナ
体験区分:調査ベース
推奨読者レベル:Level 2
何をしてくれるか
どこで出会うか
新モデル発表記事や比較記事で「Chatbot Arena ランキング上位」という表現を見かけます。lmarena.ai で自分でも対戦形式を試せ、感覚的にモデルの差を体験できます。
イメージ
開発フローでの位置
モデル選定の下調べ
自分で対戦を試す
投票で体感を数値化
自動ベンチとセットで読む
2026.04·ready
「Chatbot Arena は人間投票で ELO を積む仕組みなので、体感に近い比較ができます。」
Chatbot Arenaの見方
265
この用語の見どころ
1
役割
人間の投票を集計し、モデルの総合的な会話力を順位化します。
2
うれしさ
自動採点では測れない「読んだ感じの良さ」を数値にできます。
3
注意点
投票者の偏りや質問の分布でスコアが動くことがあります。
4
どこで役立つか
モデル選定の第一歩として、体感に近い比較軸を得られます。
5
はじめに
匿名対戦形式と ELO の仕組みが出発点です。
6
深掘り先
ELO レーティング、MMLU、SWE-Bench
非エンジニアのつまずき
- サービスの名前が頻繁に変わるので、そこが分かりづらいです
- 新製品リリース時に不自然な高順位が出ることがあり、信頼度に引っかかります。
私のコメント
- 第一印象:対戦形式なので、強いモデルがどちらか人の感覚的に分かりやすいです
- 良い点:最新の情報が反映されていて、何が賢いのかを一目で把握できるので頼りになります
- ダメな点:ランキング操作が入っていそうな違和感があり、定量性は高くありません
- 誰向けか:いま強いモデルが何かをざっくり判断したい人向けです
関連用語
備考
ELO レーティングの詳細計算式は本文では触れず、「チェスで使われる勝率ベースの点数式」という一言補足に留める。
E-50·benchmark
バイブコーディング図鑑