164 個の Python 関数生成課題で構成され、AI が書いたコードが隠しテストを通るかどうかで採点します。合格率は pass@1(1 回の出力で通る確率)という指標で表します。
ベンチマーク
236
HumanEval
ヒューマンイーバル
体験区分:調査ベース
推奨読者レベル:Level 2
何をしてくれるか
どこで出会うか
新モデルの発表記事や論文で「HumanEval スコア XX%」という形で登場します。最新モデルでは 90% 以上も多く飽和気味で、他ベンチとの比較で読むのが現実的です。
イメージ
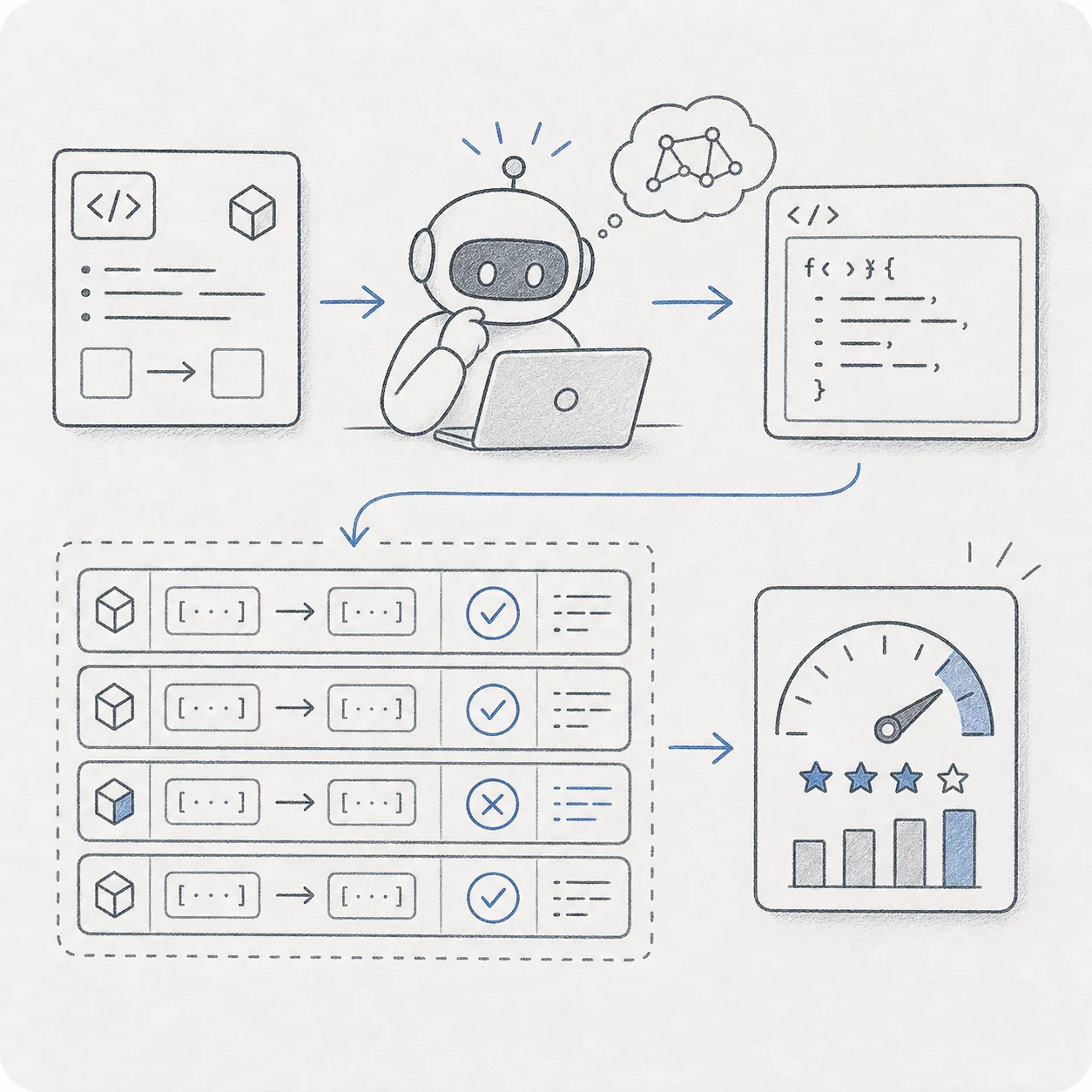
開発フローでの位置
モデル発表を確認
スコアの文脈を読む
他ベンチと比較する
自分のタスクに近いか評価
採用モデルを決める
2026.04·ready
「HumanEval は飽和気味なので、SWE-Bench も合わせて見るのが現実的です。」
HumanEvalの見方
237
この用語の見どころ
1
役割
AI のコード生成力を pass@1 で数値化する基準です。
2
うれしさ
164 問という規模で、モデル間の比較が簡単にできます。
3
注意点
Python 限定で、最新モデルでは 90%+ に達し飽和しています。
4
どこで役立つか
モデル選定の最初の足場、比較の共通言語として。
5
はじめに
pass@1 の意味と、164 問・Python 限定というスコープ。
6
深掘り先
SWE-Bench、MBPP、pass@k
非エンジニアのつまずき
- Python 評価なのに名前に Python が入らず分かりづらいです
私のコメント
- 第一印象:今回調べていて初めて見ました
- 良い点:Python コードを点数で評価できる点が良いです
- ダメな点:飽和気味で、今の最低限が分かる程度でしょうか
- 誰向けか:モデルの強さを最低限把握したい人向けです
関連用語
備考
HumanEval は 2021 年発表の古典ベンチで、Codex 評価のために作られた 最新モデルでは 90%+ を達成するものが多く、「飽和」が議論される段階にある Python 限定とい…
E-04·benchmark
バイブコーディング図鑑