SWE-Bench 全体を人手で精査し、解答可能と確認した 500 問のサブセットです。不正解が「AI の実力不足」か「問題の曖昧さ」かを切り分けられます。
ベンチマーク
232
SWE-Bench Verified
スウィーベンチベリファイド
体験区分:調査ベース
推奨読者レベル:Level 2
何をしてくれるか
どこで出会うか
新モデルの発表資料で「SWE-Bench Verified で XX%」という形で出てきます。元の全件セットより信頼性が高いため、各社が比較に使う場面が増えています。
イメージ
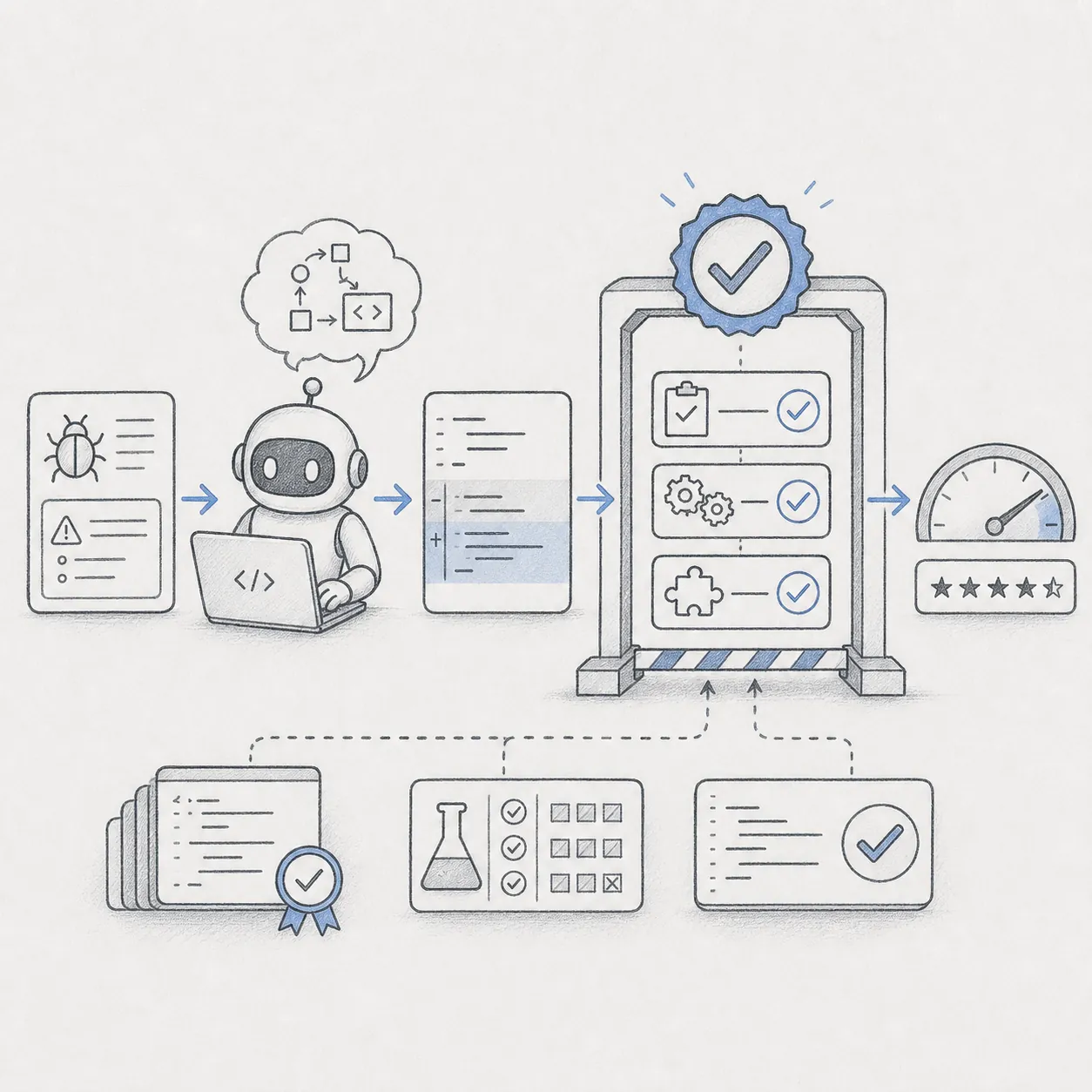
開発フローでの位置
新モデル発表を確認
スコアの前提を把握
他モデルと横比較
採用判断の補助資料にする
2026.04·ready
「比較するなら SWE-Bench Verified の数字が信頼性は高いです。」
SWE-Bench Verifiedの見方
233
この用語の見どころ
1
役割
SWE-Bench から問題品質を人手で担保した 500 問のサブセットです。
2
うれしさ
問題の曖昧さに左右されず、AI の実力を比べやすくなります。
3
注意点
500 問は全件の約 22% であり、分野の偏りが残ることがあります。
4
どこで役立つか
モデル選定時に複数サービスのスコアを横並びで比べる場面で使えます。
5
はじめに
元の SWE-Bench との関係と「人手検証」の意味を押さえると読めます。
6
深掘り先
SWE-Bench、Multi-SWE-Bench、HumanEval
非エンジニアのつまずき
- SWE-Bench 自体が不明瞭なまま「Verified」と言われても違いが掴めません。
- 何を測っているのかがイメージしにくいです。
私のコメント
- 第一印象:SWE-bench の精度向上版という印象です。
- 良い点:人手検証で信頼性を高めている点が良いと思います。
- ダメな点:既に飽和しかけている点が気になります。
- 誰向けか:モデルのコーディング性能をざっと判断したい人向けです。
関連用語
備考
SWE-Bench Verified は 2024 年に OpenAI が提案・公開したサブセット。
E-02·benchmark
バイブコーディング図鑑