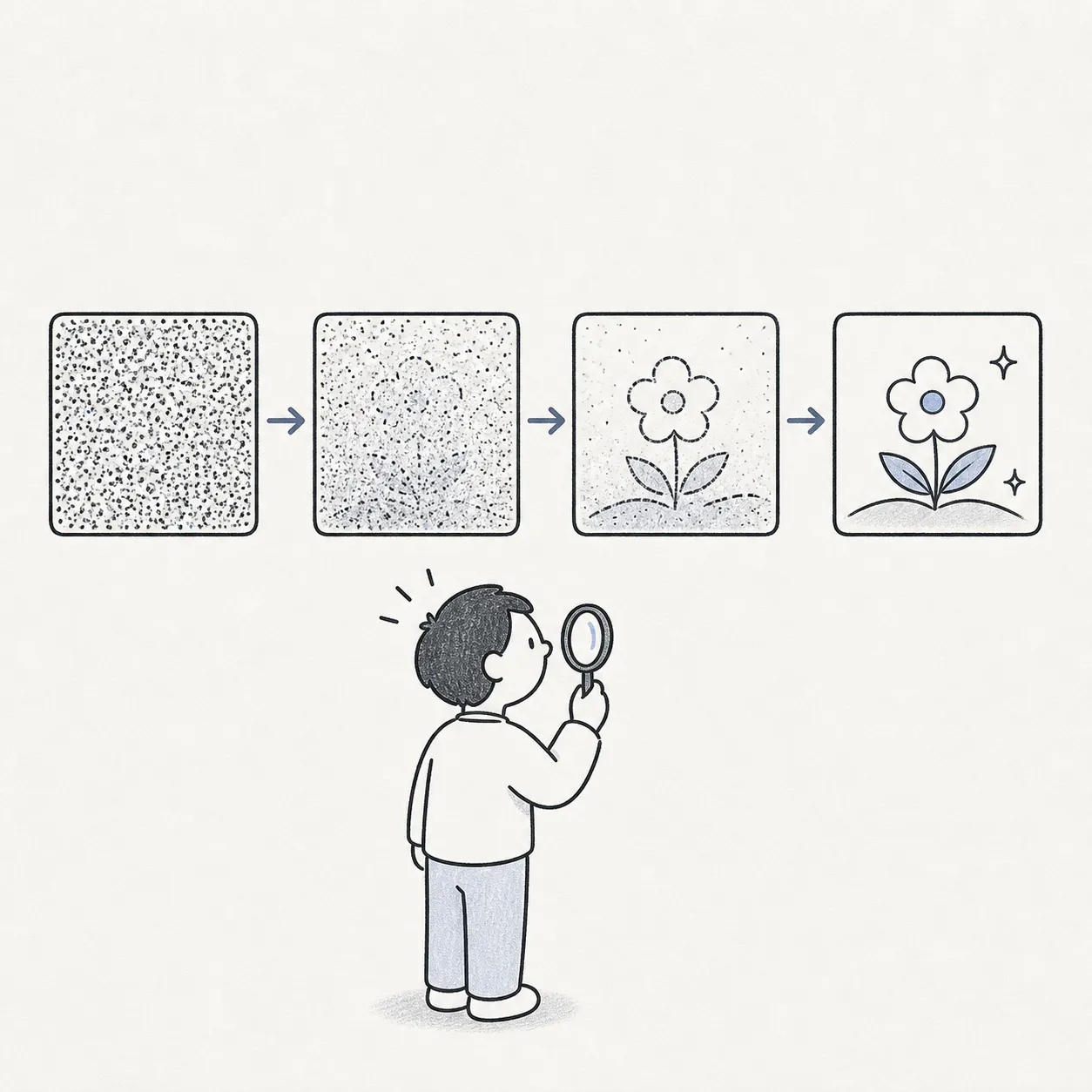
ランダムなノイズから少しずつ除去する「逆拡散」プロセスで画像や動画を生成します。テキスト条件付けを組み合わせると指示文から絵を描く AI の核になります。
一般語彙
584
拡散モデル
かくさんモデル
体験区分:調査ベース
推奨読者レベル:Level 3
何をしてくれるか
どこで出会うか
Stable Diffusion・DALL-E・Sora など画像・動画生成の解説記事で目にします。LLM と並ぶ「現代生成 AI の二大アーキテクチャ」として紹介されます。
イメージ
開発フローでの位置
モデル選定
テキスト条件の設計
推論実行
品質確認
応用実装
2026.04·ready
「Stable Diffusion は拡散モデルベースで、ノイズ除去を繰り返して画像を作ります。」
拡散モデルの見方
585
この用語の見どころ
1
役割
ノイズを段階的に除去して画像・動画・音声を生成するアーキテクチャです。
2
うれしさ
高品質な画像を多様に生成でき、テキスト指示にも対応できます。
3
注意点
複数ステップかかるため単純な推論より処理が重くなります。
4
どこで役立つか
画像・動画生成ツールの仕組みを概念として理解したい場面で役立ちます。
5
はじめに
「ノイズから絵を取り出す逆向きの処理」という大枠で十分です。
6
深掘り先
Stable Diffusion(D-54)、DDPM 論文、U-Net
非エンジニアのつまずき
- Stable Diffusion で画像生成が出てきた当初は分かりやすかったです
- GPT 系の画像・動画生成との境界がはっきり区別しきれません
私のコメント
- 第一印象:Stable Diffusion 全盛期によく耳にしました
- 良い点:ノイズ除去を繰り返してそれっぽい画像を生み出す仕組みが面白いです
- ダメな点:特に日本語のテキスト描画では文字化けが目立ちます
- 誰向けか:Stable Diffusion などで画像生成を試している人向けです
関連用語
備考
DDPM(Denoising Diffusion Probabilistic Models)の略称は本文では使わず、出典メモのみに記載。
J-23·term_general
バイブコーディング図鑑