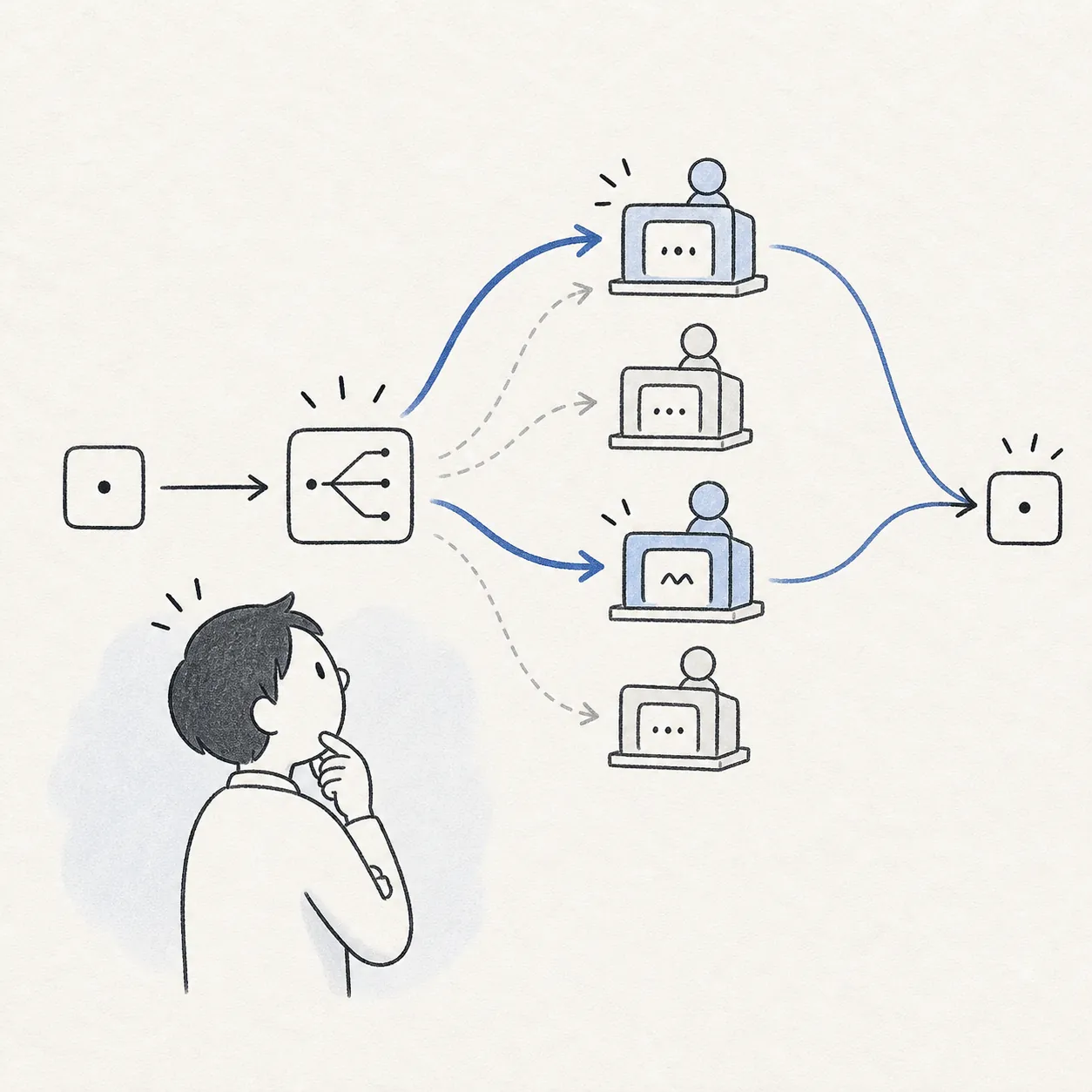
入力ごとに Router(ルーター、振り分け係)が少数の Expert(専門サブネット)だけを起動し、残りを休ませます。総パラメータが大きくても実際に使う部分は少なく、性能とコストを両立しやすくなります。
一般語彙
576
MoE
ミクスチャーオブエキスパーツ
体験区分:調査ベース
推奨読者レベル:Level 4
何をしてくれるか
どこで出会うか
「MoE アーキテクチャ採用」という表現で Mixtral や DeepSeek V3 の技術紹介に登場します。LLM(大規模言語モデル)の比較記事で「スパース MoE」と書かれていればこの仕組みを指します。
イメージ
開発フローでの位置
アーキテクチャ選択
Expert 設計
事前学習
推論・評価
利用
2026.04·ready
「MoE はルーターが Expert を選ぶ分、密なモデルより推論コストが抑えられます。」
MoEの見方
577
この用語の見どころ
1
役割
入力ごとに少数の専門家を選び、全体の効率を高めます。
2
うれしさ
総パラメータが大きくても推論コストを抑えられます。
3
注意点
ルーティングが不安定になると特定 Expert に偏りが生じます。
4
どこで役立つか
大規模モデルの性能を維持しつつコストを下げたいときに有効です。
5
はじめに
「Router が Expert を選ぶ」という大枠を押さえれば十分です。
6
深掘り先
Transformer(J-13)、LLM(J-14)、Mixtral(D-41)
非エンジニアのつまずき
- 略称だけ見ても何の略か咄嗟に出てこない用語です。
- GPT-4 系採用は噂で、クローズドゆえ「予想」止まりのもどかしさ。
私のコメント
- 第一印象:「GPT-4 はなぜ賢い」議論で名前を見たのが入り口です。
- 良い点:賢さとコスト両立のブレイクスルーで、現代モデル効率の核です。
- ダメな点:エキスパートの区切り方設計が難しく、実装上の壁は高いです。
- 誰向けか:概念だけ押さえれば充分で、全員が深掘りする必要はありません。
関連用語
備考
MoE は略称のため tagline 冒頭に「Mixture of Experts の略。
J-18·term_general
バイブコーディング図鑑