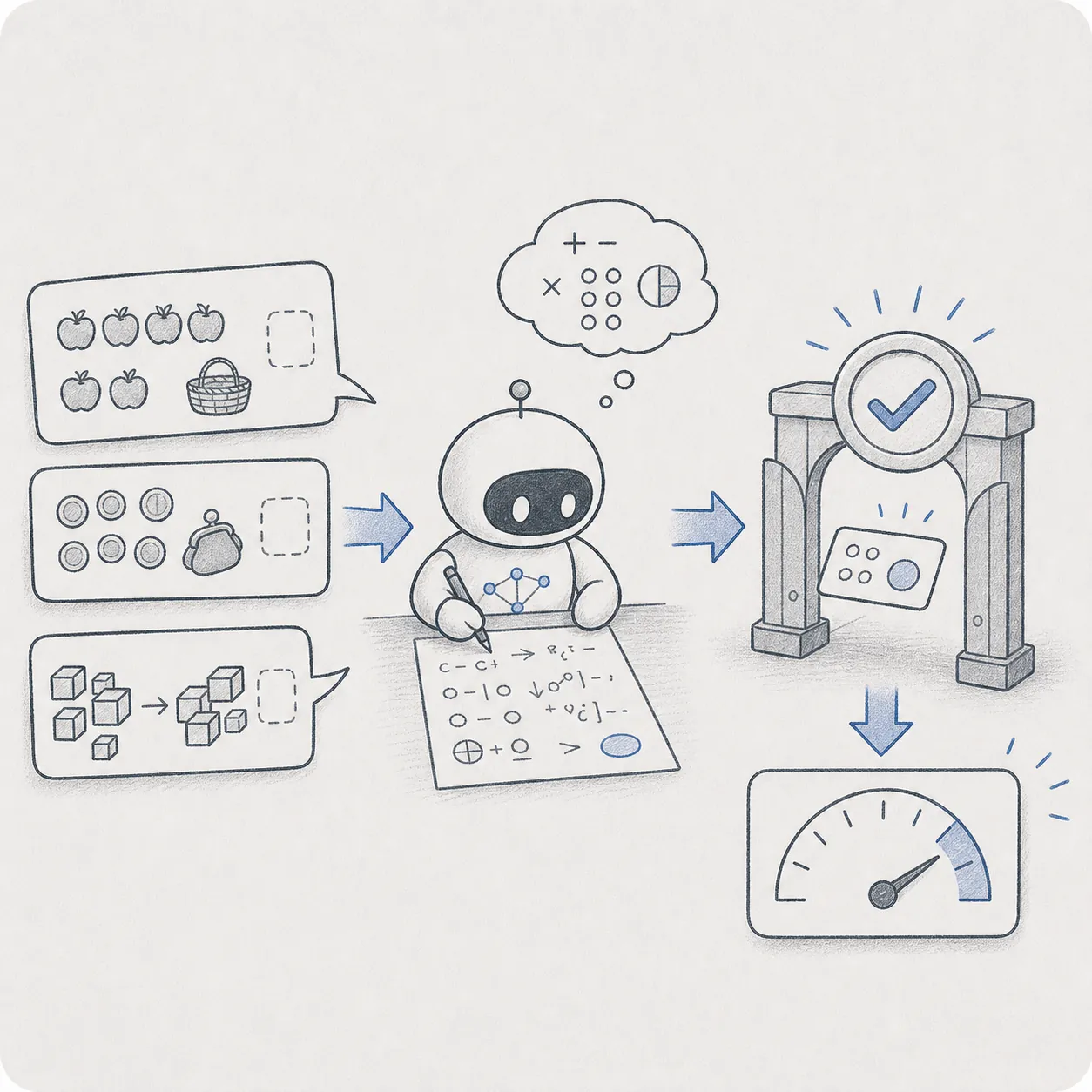
LLM が多段階の算数推論を正しく追えるかを測るベンチマークです。「リンゴが…」型の文章題を通じて、計算ステップを 1 つずつ積み上げる能力を数値化します。
ベンチマーク
244
GSM8K
ジーエスエム エイト ケー
体験区分:調査ベース
推奨読者レベル:Level 3-4
何をしてくれるか
どこで出会うか
モデル発表時の性能比較表で必ず登場します。MMLU と並ぶ定番ベンチですが、主要モデルが満点近い水準に達し、近年は「歴史的ベンチ」として位置づけられています。
イメージ
開発フローでの位置
モデル選定
性能把握
ベンチ比較
深掘り判断
2026.04·ready
「GSM8K はもう各モデルが頭打ちなので、最近は MATH や AIME で比較しています。」
GSM8Kの見方
245
この用語の見どころ
1
役割
LLM の多段階算数推論力をスコア化する評価データセットです。
2
うれしさ
問題が平易なので、スコアの意味が非エンジニアにも直感的に理解できます。
3
注意点
主要モデルが飽和済みのため、単独では現行モデルの差別化に使いにくいです。
4
どこで役立つか
モデル選定時にベンチ表を読む場面で、基準線として役立ちます。
5
はじめに
8K は 8,000 件規模のデータ数を指し、テキスト長とは無関係と押さえてください。
6
深掘り先
MATH(E-24)、AIME(E-25)、Chain of Thought(G-18)
非エンジニアのつまずき
- 今回調べていて初めて聞きました。
- 今さら追わなくてもいいベンチマークなのかなと感じ、学ぶ意欲がわきませんでした。
私のコメント
- 第一印象:今回初めて知りました。
- 良い点:定型的な性能を測るのによさそうです。
- ダメな点:高性能 LLM の差別化には使えません。
- 誰向けか:基礎から押さえたい人向けです。
関連用語
備考
「8K」はデータセット規模(約 8,000 件)を指す。
E-23·benchmark
バイブコーディング図鑑