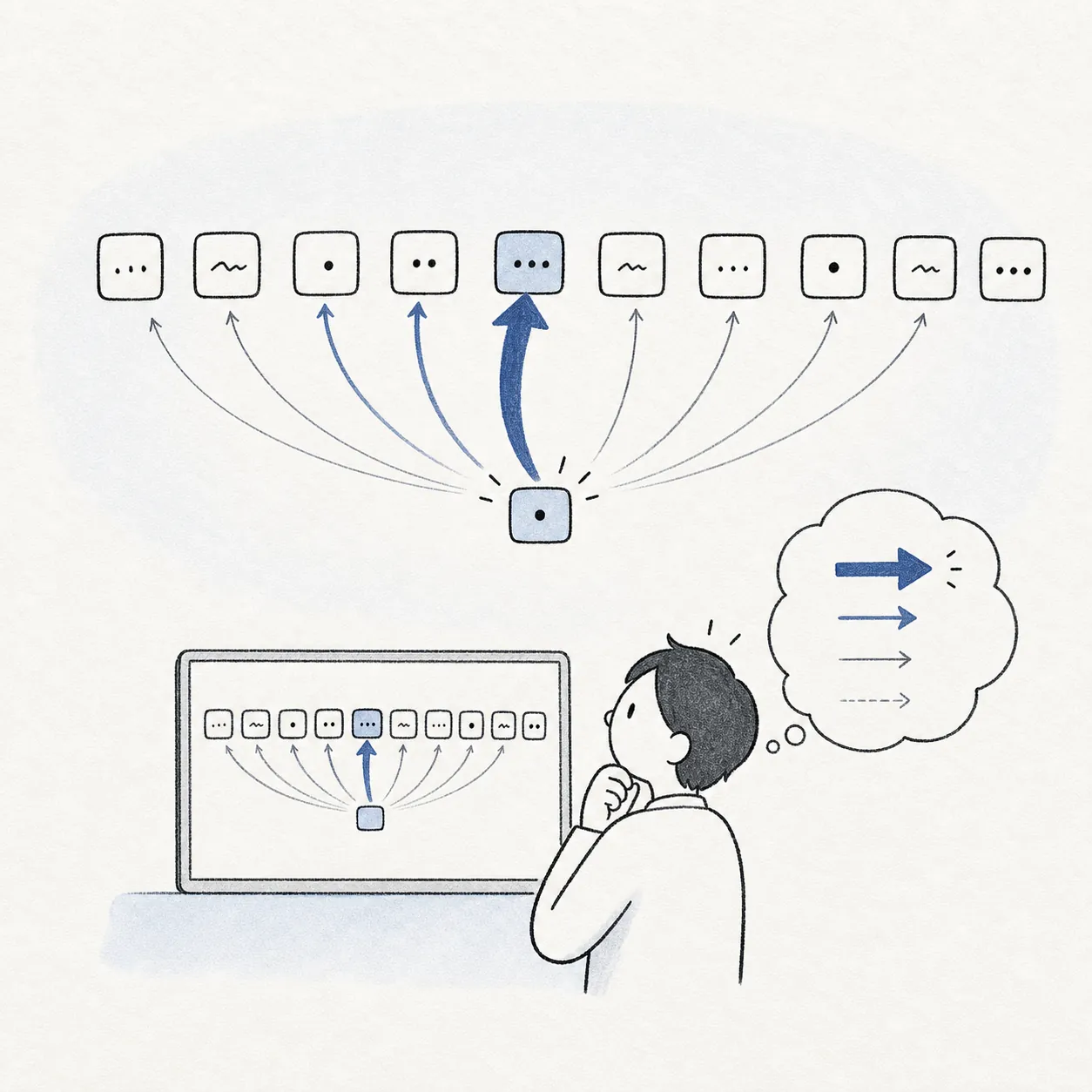
文中の各単語が他のどの単語と関係深いかを数値の重みで表します。Query(問い合わせ)・Key(索引)・Value(値)を掛け合わせて計算し、重要な単語ほど強く参照します。
一般語彙
574
Attention
アテンション
体験区分:調査ベース
推奨読者レベル:Level 3
何をしてくれるか
どこで出会うか
AI モデルの解説記事で「Self-Attention」「Multi-Head Attention」の形で目にします。ChatGPT や Claude が長い文脈を掴めるのも、この機構が並列計算で文全体を一度に処理するためです。
イメージ
開発フローでの位置
入力のトークン化
Attention の計算
重みづけ集約
多層スタック
出力生成
2026.04·ready
「Attention が文脈の鍵で、Query と Key の組み合わせで重みが変わるんですよね。」
Attentionの見方
575
この用語の見どころ
1
役割
文中の単語どうしの関係強度を数値の重みで計算します。
2
うれしさ
全単語を並列処理できるため、長い文脈も落とさず扱えます。
3
注意点
仕組みの詳細より「何に注目するか」の概念把握が先決です。
4
どこで役立つか
LLM の動作原理を理解したいときの最初の足がかりになります。
5
はじめに
Query・Key・Value の 3 語と「重みで参照する」イメージで十分です。
6
深掘り先
Transformer(J-13)、LLM(J-14)、Deep Learning(J-11)
非エンジニアのつまずき
- 詳しい人との会話で不意に出てきて躓きやすく、アテンションエコノミーとも混同しやすいです。
私のコメント
- 第一印象:Transformer の文脈で初めて目にした言葉です
- 良い点:ここを押さえると現代 LLM の原理原則を一段深く理解できます。
- ダメな点:Attention だけでは現行モデルのすごさをすべて説明できません。
- 誰向けか:原理原則を腰を据えて理解したい人にとって、必ず通る用語です
関連用語
備考
Attention は固有語のため略称展開なし。
J-17·term_general
バイブコーディング図鑑