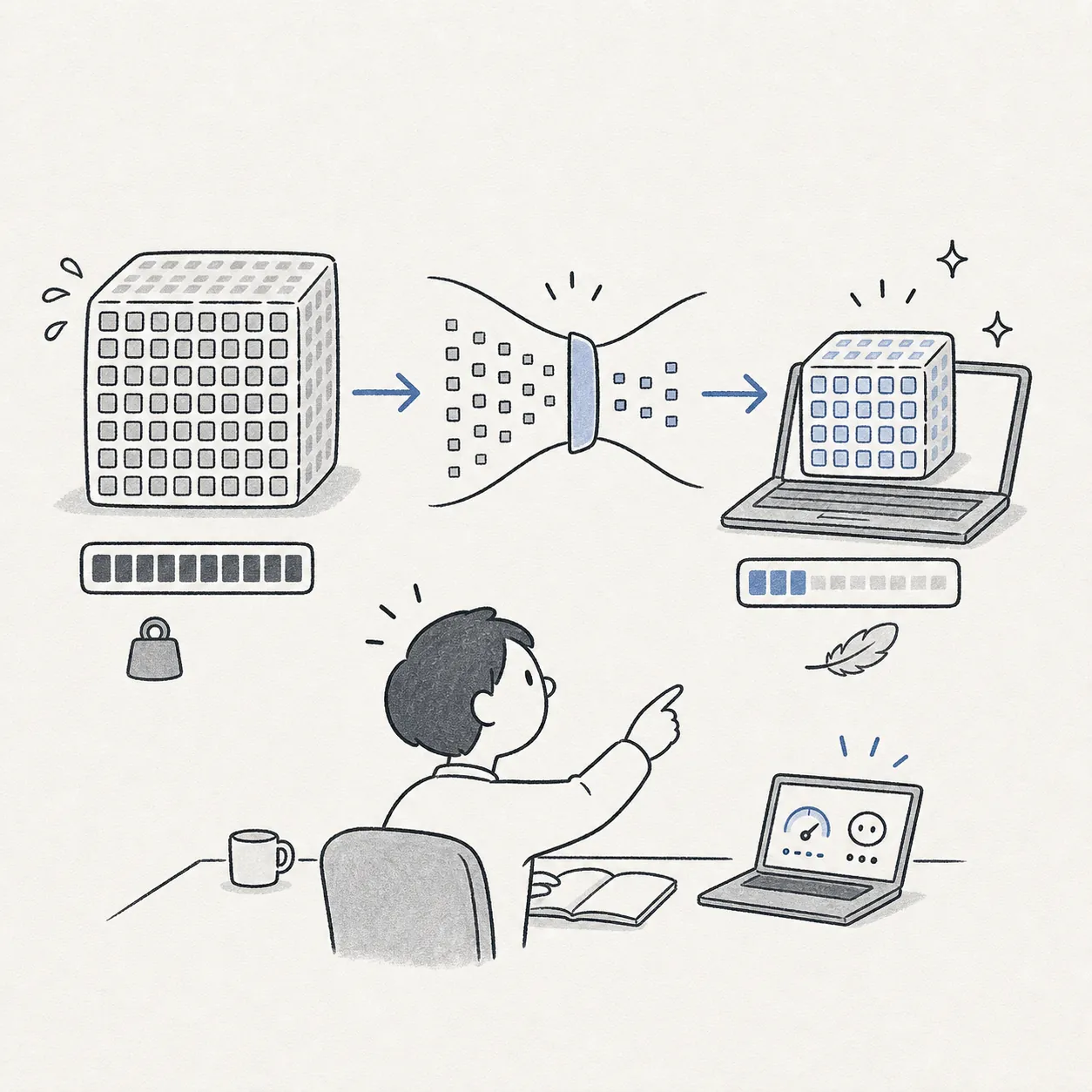
LLM のパラメータは通常 FP16 で保存されます。量子化はこれを INT8 や INT4 に圧縮し、必要な VRAM を半分以下に減らせる場合があります。
一般語彙
578
量子化
りょうしか
体験区分:少しだけ触った
推奨読者レベル:Level 3-4
何をしてくれるか
どこで出会うか
ollama や llama.cpp でモデル名に「Q4_K_M」「Q5_K_M」などの表記が並びます。Q4_K_M〜Q5_K_M がバランス推奨とされます。
イメージ
開発フローでの位置
モデル選定
VRAM 確認
モデル取得
推論実行
2026.04·ready
「Q4_K_M 量子化で Llama 3 70B が手元で動いたので、API を呼ばずに済みました。」
量子化の見方
579
この用語の見どころ
1
役割
モデル重みのビット数を下げてメモリを節約します。
2
うれしさ
一般 PC でも大型モデルをローカル動作できます。
3
注意点
精度がわずかに落ちる場合があります(FP16 比 1〜5% 程度)。
4
どこで役立つか
ローカル LLM 構築や API コスト削減に役立ちます。
5
はじめに
Q4_K_M がバランス推奨という目安を覚えると入門に十分です。
6
深掘り先
GGUF、AWQ、bitsandbytes
非エンジニアのつまずき
- 「量子化」という言葉が硬く、性能トレードオフを感覚的に掴みづらいです
- フロンティアモデルのレンジ分けに量子化のコツがあるはずですが、表に出ない部分が多いです
私のコメント
- 第一印象:モデル名の 4bit / 8bit 表記で量子化を知りました。
- 良い点:スマホでも動くモデルが出てきてエッジ実行の可能性が広がります。
- ダメな点:やりすぎると性能劣化が顕著になります。
- 誰向けか:リソース制約の環境でモデルを動かしたい人向けです。
関連用語
備考
Q4_K_M / Q5_K_M は GGUF 形式(llama.cpp 由来)の量子化レベル表記。
J-19·term_general
バイブコーディング図鑑